
Andrey Puentes M.
Solutions Specialist
Azure Synapse Analytics es un servicio que reúne la integración de datos, el almacenamiento de datos empresariales y el análisis de big data por medio de tecnologías como: SQL, para almacenar datos; pipelines, para integración de datos por medio de procesos ETL; y, además, integración con otros servicios como Power BI, CosmosDB y AzureML. [1]
Al usar este servicio para la creación de un data warehouse se hace imprescindible el uso e integración de servicios de almacenamiento para la creación del repositorio de datos, tambien conocido como data lake. Dependiendo del diseño del data lake se pueden tener diferentes niveles de almacenamiento, desde los datos brutos extraídos hasta los datos listos para ser alimentados en el data warehouse, sin embargo, es necesario conocer las características propias de los datos en cada nivel con el fin de tomar mejores decisiones para su extracción, transformación y carga. [2]
Por otro lado, SQL es uno de los lenguajes de consulta más utilizados para trabajar con datos en el mundo, permitiendo recuperar, filtrar y agregar datos comúnmente en bases de datos relacionales [3]. De este modo, una alterativa para obtener una comprensión más profunda de los datos almacenados en los diferentes niveles de un data lake es el uso de Azure Synapse Analytics serverless SQL pool, el cual permite ejecutar consultas SQL a diferentes formatos de archivos almacenados en el data lake como PARQUET, CSV y JSON, y así, realizar un análisis y exploración de estos, permitiendo razonar acerca de su contenido y estructura, logrando una mejor interpretación de las transformaciones necesarias en el proceso y las relaciones entre los diferentes origenes.
Para lograr lo anterior es necesario contar con un servicio de Azure Synapse Analytics desplegado, donde al crear un espacio de trabajo de Synapse se especifica un Data Lake Storage Gen2 como ubicación predeterminada para logs y job output; este servicio de almacenamiento será utilizado en el presente documento para ejemplificar la ejecución de consultas SQL por medio de Serverless SQL pool [4]. Para conocer como desplegar un servicio de Azure Synapse Analytics, la siguiente documentación de Microsoft funciona como guía: https://learn.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-workspace.
Consultas SQL por medio de Serverless SQL pool
- Luego de desplegar Azure Synapse Analytics se debe tener dentro del grupo de recursos utilizado un servicio de Storage account (Data Lake Storage Gen2) y otro de Synapse workspace

- Al ingresar en los contenedores del Storage account se podrá observar un solo contenedor el cual se encuentra dispuesto para el almacenamiento de logs y job output, por lo que se ha creado un contenedor adicional para el almacenamiento de los archivos a consultar, ‘row-data-csv’.
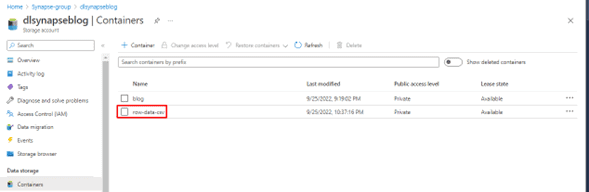 Como ejemplo, se ha cargado un archivo CSV dentro de la carpeta ‘row-data-csv’.
Como ejemplo, se ha cargado un archivo CSV dentro de la carpeta ‘row-data-csv’.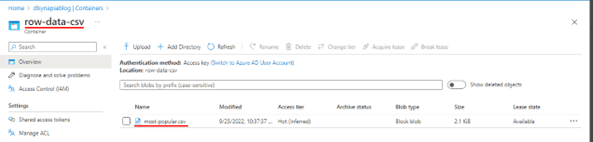
- Con los recursos desplegados y el almacenamiento del archivo a consultar listo, se debe continuar con la conexión a SQL server management studio (SSMS) por medio del Serverles SQL endpoint, el cual se obtiene desde la descripción general del espacio de trabajo de Synapse.

- Para ingresar en SSMS se toma como Server name el Serverless SQL endpoint y como Authentication se selecciona Azure AD Multifactor authentication, lo que nos permite acceder por medio de las credenciales de la cuenta de Azure, por lo que el User name será el email relacionado con la cuenta en Azure y luego de esto se pedirá ingresar la contraseña de la cuenta


- Luego de ingresar, podremos observar que nos hemos conectado a un servicio SQL server On-demand, es decir, el servicio de consulta serverless por medio del cual podremos ejecutar consultas SQL a los archivos almacenados en el data lake. Sin embargo, es importante señalar que un usuario que haya iniciado sesión en el servicio de Synapse Serverless SQL pool debe estar autorizado para acceder y consultar los archivos en Azure Storage.
- Una vez conectados, es posible utilizar la función OPENROWSET para leer el contenido de archivos en el data lake. Para leer directamente el contenido de los archivos se debe especificar la ubicación URL como BULK opción [6]. En general, para consultar un archivo se utiliza el siguiente Script:
SELECT *
FROM OPENROWSET (BULK ‘http://<storage account>.dfs.core.windows.net/container/folder/file/’,
FORMAT = ‘FORMAT_FILE’) AS [file]
Sin embargo, dependiendo del formato del archivo se pueden necesitar parámetros adicionales. A continuación, se encuentra la documentación oficial de Microsoft para consultar en detalle las diferentes opciones a utilizar para la consulta de archivos JSON, CSV y PARQUET por medio de Synapse Serverless SQL pool:
- JSON: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/query-json-files
- CSV: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/query-single-csv-file
- PARQUET: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/query-parquet-files
- En el ejemplo realizado el archivo a consultar se encuentra en formato CSV, nombrado como ‘most-popular.csv’ y almacenado en un contenedor llamado ‘row-data-csv’ el cual pertenece al Storage Account ‘dlsynapseblog’. Adicionalmente, en el caso de archivos CSV es necesario especificar los parámetros ‘PARSER_VERSION’ y ‘HEADER_ROW’ para determinar cual es el terminador de cada fila y si el archivo consultado posee la primera fila como encabezado respectivamente.
De esta manera el Script para consultar el archivo de ejemplo sería:
SELECT *
FROM OPENROWSET (BULK ‘https://dlsynapseblog.blob.core.windows.net/row-data-csv/most-popular.csv’, FORMAT =’CSV’, parser_version = ‘2.0’, HEADER_ROW = TRUE) AS [file]

Luego de ejecutar la consulta podremos observar el contenido de los archivos almacenados en el data lake, por lo que a primera vista podemos explorar que tipo de información se esta almacenando, verificar existencia de llaves primarias, conocer el tipo de dato de cada atributo y la existencia de valores nulos o no dentro de cada uno de ellos. Adicionalmente, una de las ventajas de Synapse Serverless SQL pool es que permite utilizar funciones de agregación y cláusulas dentro de las consultas, de esta manera es posible realizar validaciones como por ejemplo revisar la cantidad de registros que debe haber en cierto nivel del data lake o revisar si la suma de alguna cantidad se encuentra entre los valores esperados.
Así, continuando con el ejemplo, es posible determinar la cantidad de registros cuyo atributo ‘season_title’ no sea nulo por medio del uso de una función de agregación como lo es COUNT() y la cláusula WHERE:
SELECT COUNT(*) AS Records_with_not_null_season
FROM OPENROWSET (BULK ‘https://dlsynapseblog.blob.core.windows.net/row-data-csv/most-popular.csv’,FORMAT =’CSV’, parser_version = ‘2.0’, HEADER_ROW = TRUE) AS [file]
WHERE season_title is not Null
- Por otro lado, Synapse Serverless SQL pool no solo permite realizar consultas a un solo archivo, sino que es posible consultar una carpeta que contenga varios archivos, siempre y cuando cada uno de los archivos dentro de la carpeta posean una misma estructura con el fin de mantener consistencia en lo datos consultados.

Para lograr lo anterior se debe especificar /** al final de la ruta, de lo contrario no se podrán consultar los datos. Asimismo, Synapse Serverless SQL pool no retorna resultados para archivos cuyo nombre comienza con un subrayado (_) o un punto (.). [6]
Así, si cargamos el archivo utilizado como ejemplo tres veces dentro de una misma carpeta en el data lake:\
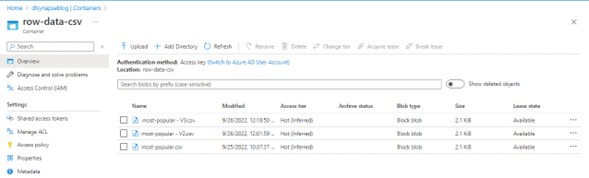
Y donde solo uno de los archivos será nombrado con un punto (.) al inicio, se observa que al hacer la consulta de conteo de registros con el atributo ‘season_title’ no nulo, el resultado es solamente el doble respecto a los resultados obtenidos con un único archivo, esto debido a las restricciones antes mencionadas, por lo que la consulta se hace realmente sobre archivos cuyo nombre no empieza por punto (.).
SELECT COUNT(*) AS Records_with_not_null_season
FROM OPENROWSET (BULK ‘https://dlsynapseblog.blob.core.windows.net/row-data-csv/**’, FORMAT =’CSV’, parser_version = ‘2.0’, HEADER_ROW = TRUE) AS [file]
WHERE season_title is not Null
De acuerdo con lo anterior, y luego de entender el funcionamiento y uso de Azure Synapse Analytics serverless SQL pool para la ejecución de consultas a un Storage Account, se pueden resumir las siguientes ventajas:
Ventajas de Serverless SQL pool
- Uso de una de una sintaxis ampliamente conocida (T-SQL) para la consulta de datos desde el data lake sin necesidad de copiar los datos.
- Facilita el descubrimiento y exploración de datos almacenados en el data lake en múltiples formatos (PARQUET, CSV, JSON).
- No es necesario especificar un esquema en las consultas ya que se infieren automáticamente.
- Es posible no solo consultar un archivo a la vez si no tambien carpetas con múltiples archivos.
- El costo de utilizar este servicio maneja un modelo pay-per-use, por lo que solo se cobra de acuerdo con los datos procesados por las consultas que se ejecutan.
Referencias:
[1] What is Azure Synapse Analytics?. (2022). Recuperado 26 de septiembre de 2022, de Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/overview-what-is
[2] Big data analytics with enterprise-grade security using Azure Synapse. (2022). Recuperado 26 de septiembre de 2022, de Microsoft website: https://learn.microsoft.com/en-us/azure/architecture/solution-ideas/articles/big-data-analytics-enterprise-grade-security
[3] Query files using a serverless SQL pool. (2022). Recuperado 26 de septiembre de 2022, de Microsoft website: https://microsoftlearning.github.io/DP-500-Azure-Data-Analyst/Instructions/labs/01-analyze-data-with-sql.html
[4] Quickstart: Create a Synapse workspace. (2022). Recuperado 26 de septiembre de 2022, de Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-workspace
[5] Serverless SQL pool in Azure Synapse Analytics. (2022). Recuperado 26 de septiembre de 2022, de Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/on-demand-workspace-overview
[6] How to use OPENROWSET using serverless SQL pool in Azure Synapse Analytics. (2022). Recuperado 26 de septiembre de 2022, de Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/develop-openrowset