
Andrey Puentes M.
Solutions Specialist
Azure Synapse Analytics is a service that brings together data integration, enterprise data warehousing and big data analytics through technologies such as: SQL, for data warehousing; pipelines, for data integration through ETL processes; and, in addition, integration with other services such as Power BI, CosmosDB and AzureML. [1]
When using this service for the creation of a data warehouse, it is essential to use and integrate storage services for the creation of the data repository, also known as data lake. Depending on the design of the data lake, it is possible to have different storage levels, from raw data extracted to data ready to be fed into the data warehouse, however, it is necessary to know the characteristics of the data at each level in order to make better decisions for its extraction, transformation and loading. [2]
On the other hand, SQL is one of the most widely used query languages for working with data in the world, allowing to retrieve, filter and aggregate data commonly in relational databases [3]. Thus, an alternative to obtain a deeper understanding of the data stored at different levels of a data lake is the use of Azure Synapse Analytics serverless SQL pool, which allows to execute SQL queries to different file formats stored in the data lake as PARQUET, CSV and JSON, and thus, perform an analysis and exploration of these, allowing reasoning about their content and structure, achieving a better interpretation of the necessary transformations in the process and the relationships between the different sources.
To achieve the above it is necessary to have an Azure Synapse Analytics service deployed, where when creating a Synapse workspace a Data Lake Storage Gen2 is specified as the default location for logs and job output; this storage service will be used in this document to exemplify the execution of SQL queries by means of Serverless SQL pool [4]. To learn how to deploy an Azure Synapse Analytics service, the following Microsoft documentation works as a guide: https://learn.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-workspace.
SQL queries through the Serverless SQL pool
- After deploying Azure Synapse Analytics you must have a Storage account (Data Lake Storage Gen2) and a Synapse workspace service within the resource group used.

- When you enter the Storage account containers you will see only one container which is arranged for the storage of logs and job output, so an additional container has been created for the storage of the files to be consulted, 'row-data-csv'.
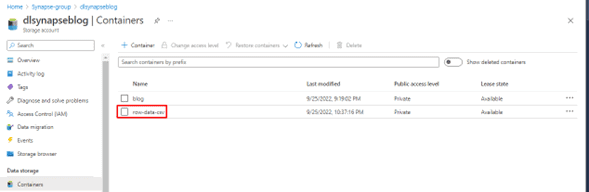 As an example, a CSV file has been loaded into the 'row-data-csv' folder.
As an example, a CSV file has been loaded into the 'row-data-csv' folder.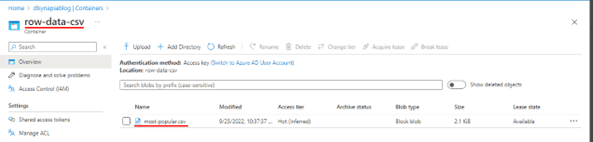
- With the resources deployed and the storage of the file to query ready, continue with the connection to the SQL server management studio (SSMS) through the Serverles SQL endpoint, which is obtained from the Synapse workspace overview.

- To enter SSMS Serverless SQL endpoint is taken as Server name and as Authentication Azure AD Multifactor authentication is selected, which allows us to access through the credentials of the Azure account, so the User name will be the email related to the Azure account and after this will be asked to enter the password of the account


- After logging in, we can see that we have connected to a SQL server On-demand service, that is, the serverless query service through which we can execute SQL queries to the files stored in the data lake. However, it is important to note that a user logged into the Synapse Serverless SQL pool service must be authorized to access and query the files in Azure Storage.
- Once connected, it is possible to use the OPENROWSET function to read the content of files in the data lake. To read directly the content of the files, the URL location must be specified as BULK option [6]. In general, the following script is used to query a file:
SELECT *
FROM OPENROWSET (BULK ‘http://<storage account>.dfs.core.windows.net/container/folder/file/’,
FORMAT = 'FORMAT_FILE') AS [file]) AS [file]
However, depending on the file format, additional parameters may be required. Below is the official Microsoft documentation to consult in detail the different options to use for querying JSON, CSV and PARQUET files through Synapse Serverless SQL pool:
- JSON: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/query-json-files
- CSV: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/query-single-csv-file
- PARQUET: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/query-parquet-files
- In the example given the file to be queried is in CSV format, named 'most-popular.csv' and stored in a container named 'row-data-csv' which belongs to the Storage Account 'dlsynapseblog'. Additionally, in the case of CSV files it is necessary to specify the parameters 'PARSER_VERSION' and 'HEADER_ROW' to determine which is the terminator of each row and if the queried file has the first row as header respectively.
Thus the script to query the example file would be:
SELECT *
FROM OPENROWSET (BULK 'https://dlsynapseblog.blob.core.windows.net/row-data-csv/most-popular.csv', FORMAT ='CSV', parser_version = '2.0', HEADER_ROW = TRUE) AS [file]

After executing the query we can observe the content of the files stored in the data lake, so at first glance we can explore what kind of information is being stored, verify the existence of primary keys, know the data type of each attribute and the existence of null values or not within each of them. Additionally, one of the advantages of Synapse Serverless SQL pool is that it allows the use of aggregation functions and clauses within the queries, in this way it is possible to perform validations such as checking the number of records that should be in a certain level of the data lake or checking if the sum of some quantity is between the expected values.
Thus, continuing with the example, it is possible to determine the number of records whose 'season_title' attribute is not null by using an aggregation function such as COUNT() and the WHERE clause:
SELECT COUNT(*) AS Records_with_not_null_season
FROM OPENROWSET (BULK 'https://dlsynapseblog.blob.core.windows.net/row-data-csv/most-popular.csv',FORMAT ='CSV', parser_version = '2.0', HEADER_ROW = TRUE) AS [file]
WHERE season_title is not Null
- On the other hand, Synapse Serverless SQL pool not only allows querying a single file, but it is also possible to query a folder containing several files, as long as each of the files within the folder have the same structure in order to maintain consistency in the queried data.

To achieve this, /** must be specified at the end of the path, otherwise the data will not be queried. Also, Synapse Serverless SQL pool does not return results for files whose name begins with an underscore (_) or a period (.). [6]
Thus, if we load the file used as an example three times into the same folder in the data lake:\.
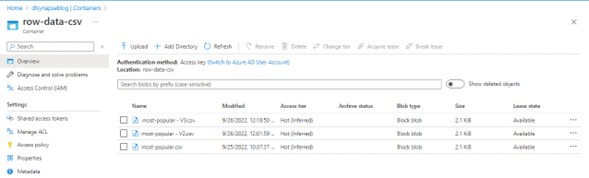
And where only one of the files will be named with a dot (.) at the beginning, it is observed that when doing the record count query with the non-null 'season_title' attribute, the result is only double with respect to the results obtained with a single file, this due to the above mentioned restrictions, so the query is actually done on files whose name does not start with a dot (.).
SELECT COUNT(*) AS Records_with_not_null_season
FROM OPENROWSET (BULK 'https://dlsynapseblog.blob.core.windows.net/row-data-csv/**', FORMAT ='CSV', parser_version = '2.0', HEADER_ROW = TRUE) AS [file]
WHERE season_title is not Null
According to the above, and after understanding the operation and use of Azure Synapse Analytics serverless SQL pool for the execution of queries to a Storage Account, the following advantages can be summarized:
Advantages of Serverless SQL pool
- Use of a widely known syntax (T-SQL) for querying data from the data lake without the need to copy the data.
- Facilitates the discovery and exploration of data stored in the data lake in multiple formats (PARQUET, CSV, JSON).
- It is not necessary to specify a schema in the queries as they are automatically inferred.
- It is possible to consult not only one file at a time but also folders with multiple files.
- The cost of using this service is based on a pay-per-use model, so it is only charged according to the data processed by the queries that are executed.
References:
[1] What is Azure Synapse Analytics (2022). Retrieved September 26, 2022, from Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/overview-what-is
[2] Big data analytics with enterprise-grade security using Azure Synapse (2022). Retrieved September 26, 2022, from Microsoft website: https://learn.microsoft.com/en-us/azure/architecture/solution-ideas/articles/big-data-analytics-enterprise-grade-security
[3] Query files using a serverless SQL pool (2022). Retrieved September 26, 2022, from Microsoft website: https://microsoftlearning.github.io/DP-500-Azure-Data-Analyst/Instructions/labs/01-analyze-data-with-sql.html
[4] Quickstart: Create a Synapse workspace (2022). Retrieved September 26, 2022, from Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-workspace
[5] Serverless SQL pool in Azure Synapse Analytics (2022). Retrieved September 26, 2022, from Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/on-demand-workspace-overview
[6] How to use OPENROWSET using serverless SQL pool in Azure Synapse Analytics (2022). Retrieved September 26, 2022, from Microsoft website: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/develop-openrowset